

Introduction:
Machine learning algorithms are the backbone of modern AI systems, enabling computers to learn and make intelligent decisions from data. In this article, we will delve into the world of machine learning algorithms, focusing on prominent ones like KNN (K-Nearest Neighbors), Random Forest, Naive Bayes, Decision Tree, Classification, and Genetic Algorithms. Additionally, we will explore different types of algorithms used in machine learning. Understanding these algorithms is essential for any aspiring data scientist or AI enthusiast.
Understanding Machine Learning Algorithms
KNN Algorithm in Machine Learning
Introduction to KNN Algorithm
 |
| Image Source |
The KNN (K-Nearest Neighbors) algorithm is a simple yet powerful technique used for both classification and regression tasks. It works on the principle of finding the k nearest data points in the training set to make predictions or estimations. KNN considers the class labels or values of the nearest neighbors and assigns the most common class label (in classification) or the average value (in regression) as the prediction. One of the advantages of KNN is its simplicity and ease of implementation. However, it may suffer from slower computation times when dealing with large datasets. KNN is widely used in recommendation systems, image recognition, and anomaly detection. [Source]
Random Forest Algorithm in Machine Learning


Overview of Random Forest
Random Forest is an ensemble learning algorithm that combines multiple decision trees to improve prediction accuracy and reduce overfitting. It creates a diverse set of decision trees by introducing randomness during the tree-building process. Each decision tree in the Random Forest is trained on a different subset of the data and considers a random subset of features. During prediction, the output of each decision tree is combined to make the final prediction. Random Forest is known for its robustness, scalability, and effectiveness in handling high-dimensional datasets. It finds applications in areas like credit scoring, fraud detection, and bioinformatics. [Source]
Naive Bayes Algorithm in Machine Learning

The Concept of Naive Bayes
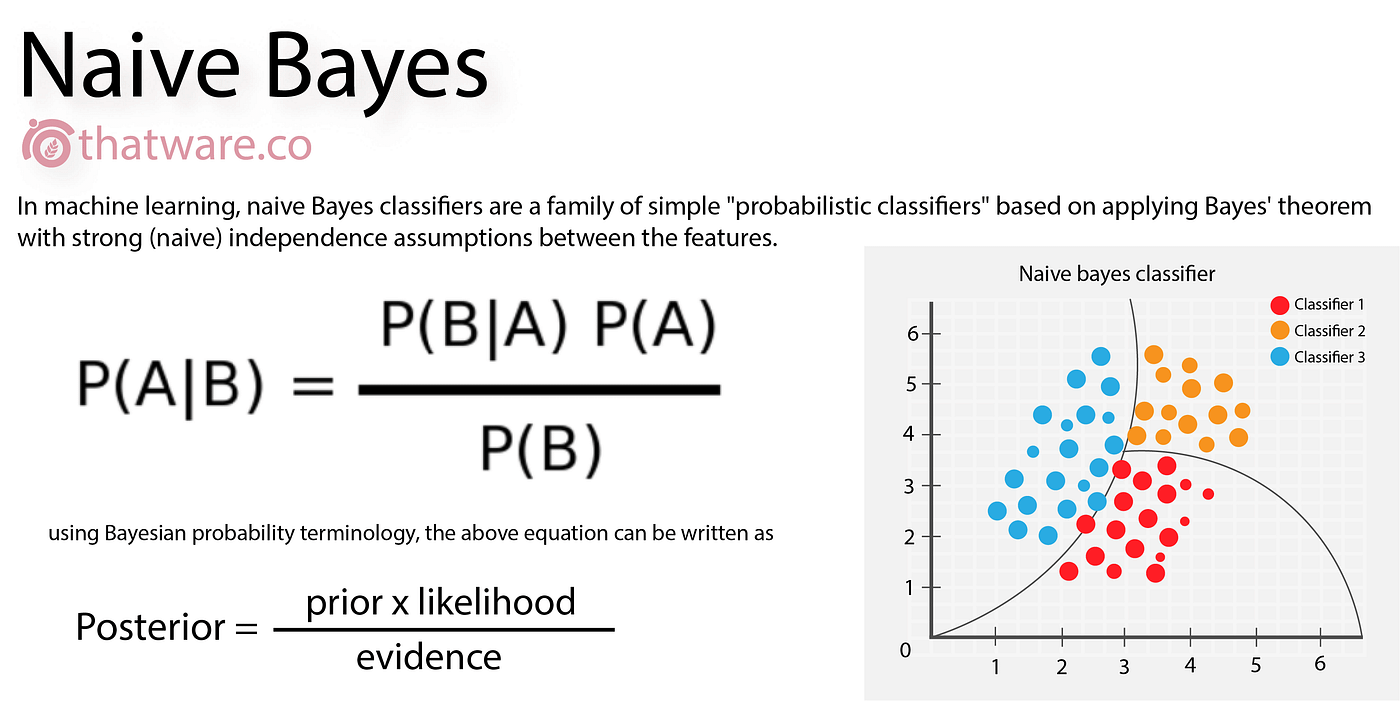
Naive Bayes is a probabilistic algorithm based on Bayes' theorem. It assumes that features are independent of each other, which simplifies the calculation of probabilities. Naive Bayes is particularly useful for text classification tasks, such as spam filtering or sentiment analysis. It leverages the probability of observing certain words in a given class to make predictions. Despite its "naive" assumption of feature independence, Naive Bayes has shown remarkable performance in various domains. Its simplicity, efficiency, and ability to handle high-dimensional data make it a popular choice. [Source]
Decision Tree Algorithm in Machine Learning
Unveiling Decision Tree Algorithm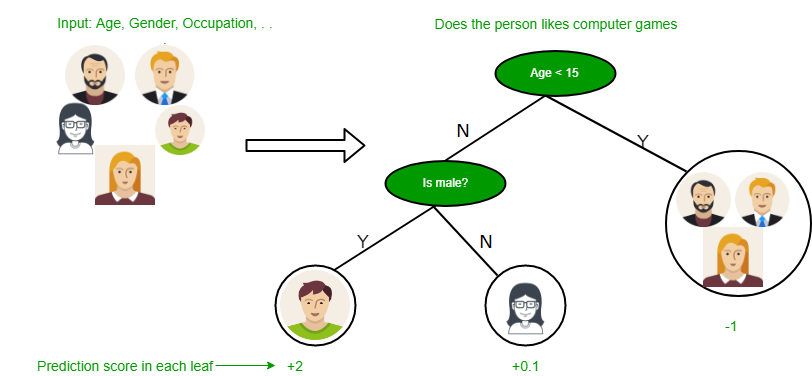
Source
Decision Tree algorithm is a versatile and interpretable machine learning technique that builds a tree-like model of decisions and their possible consequences. It partitions the input space based on features and their thresholds to create a hierarchical structure. Each internal node represents a decision based on a feature, and each leaf node represents a predicted class or value. Decision Trees are commonly used in credit scoring, customer churn prediction, and medical diagnosis. They offer transparency, as the decision paths can be easily interpreted. However, decision trees are prone to overfitting if not properly regularized. Various techniques like pruning, ensemble methods (e.g., Random Forest), or boosting can be applied to improve decision tree performance. [Source]
Machine Learning Classification Algorithms
Key Classification Algorithms
Classification algorithms are a fundamental component of machine learning, enabling the categorization of data into predefined classes or categories. Apart from the aforementioned KNN, Random Forest, Naive Bayes, and Decision Tree algorithms, other popular classification algorithms include Support Vector Machines (SVM), Logistic Regression, and Neural Networks. Support Vector Machines find optimal decision boundaries between classes, Logistic Regression models the probability of each class, and Neural Networks mimic the structure and function of the human brain to learn complex patterns. Each algorithm has its strengths and weaknesses, making them suitable for specific tasks. [Source]
Genetic Algorithm in Machine Learning
Evolutionary Computation with Genetic Algorithm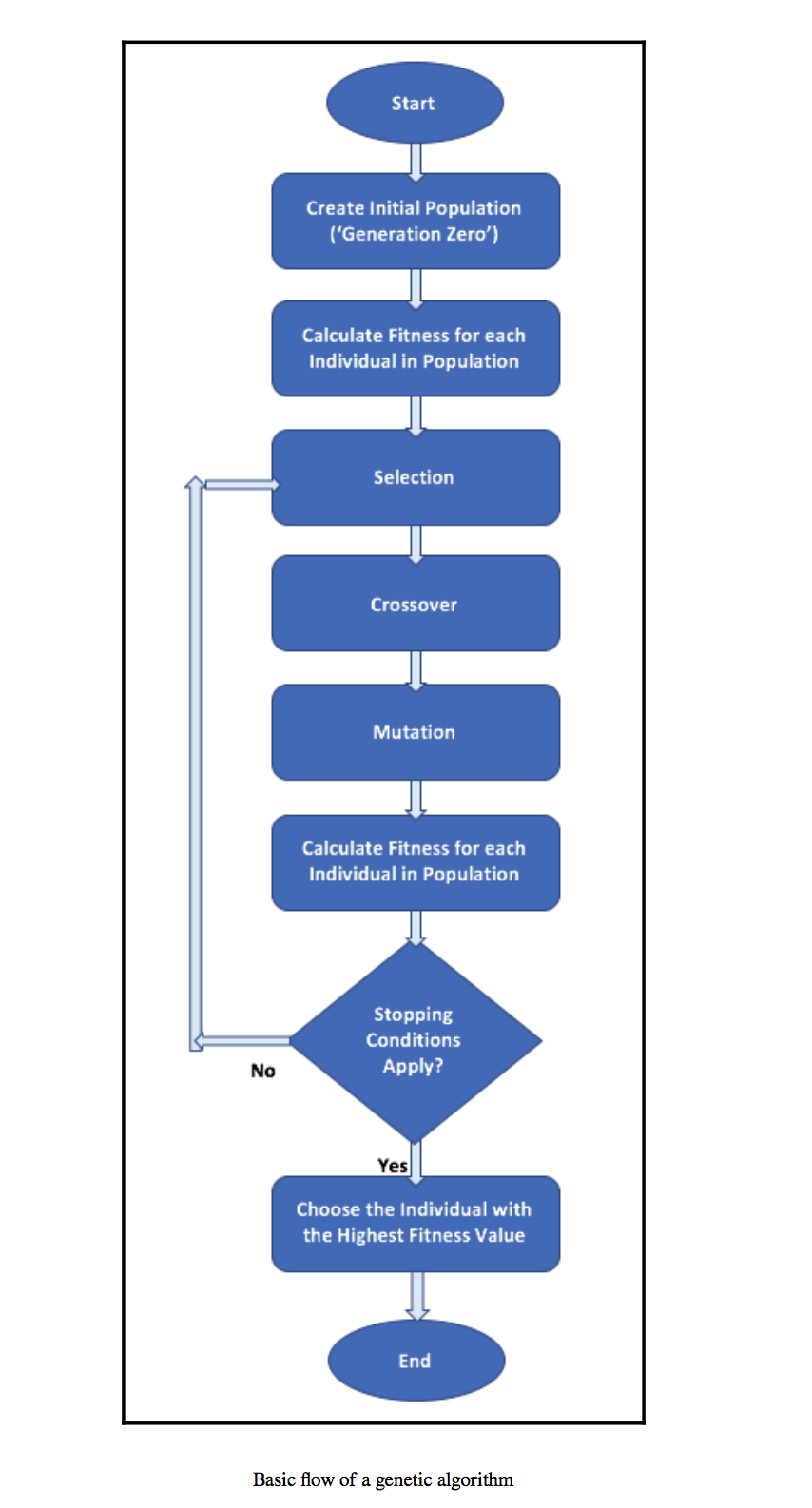
Source
Genetic Algorithms are inspired by the process of natural selection and genetic evolution. They optimize solutions by mimicking the concepts of survival of the fittest, crossover, and mutation. Genetic Algorithms start with an initial population of candidate solutions and iteratively evolve and refine them to find the best solution. They find applications in optimization problems, feature selection, and neural network training. Genetic Algorithms offer a powerful approach for solving complex, multi-dimensional optimization challenges. They can effectively handle a large search space and have the potential to discover optimal or near-optimal solutions. [Source]
Types of Algorithms in Machine Learning
Supervised Learning Algorithms
Supervised learning algorithms learn from labeled training data, where each data instance has corresponding class labels or target values. These algorithms aim to generalize the patterns present in the training data to make predictions on unseen data. KNN, Random Forest, Naive Bayes, Decision Tree, and Classification algorithms fall under the category of supervised learning algorithms.
Unsupervised Learning Algorithms
Unsupervised learning algorithms operate on unlabeled data, seeking to discover inherent patterns or structures without explicit class labels or target values. Clustering algorithms, such as K-means and Hierarchical Clustering, and dimensionality reduction techniques like Principal Component Analysis (PCA) and t-SNE are examples of unsupervised learning algorithms. These algorithms enable data exploration, grouping similar instances together, and reducing the dimensionality of data.
Reinforcement Learning Algorithms
Reinforcement learning algorithms learn through interactions with an environment, aiming to maximize a reward signal. These algorithms learn by trial and error, taking actions and receiving feedback in the form of rewards or penalties. They optimize a policy that maps states to actions to maximize cumulative rewards. Reinforcement learning has found success in game-playing agents, autonomous vehicles, and robotics.
Conclusion:
Machine learning algorithms are diverse and powerful tools that enable computers to learn and make intelligent decisions from data. In this article, we explored various algorithms, including KNN, Random Forest, Naive Bayes, Decision Tree, Classification, and Genetic Algorithms. Additionally, we discussed different types of algorithms used in machine learning, such as supervised learning, unsupervised learning, and reinforcement learning. Understanding these algorithms and their applications is essential for anyone interested in the exciting field of data science and AI.

{kind=link}
0 Comments